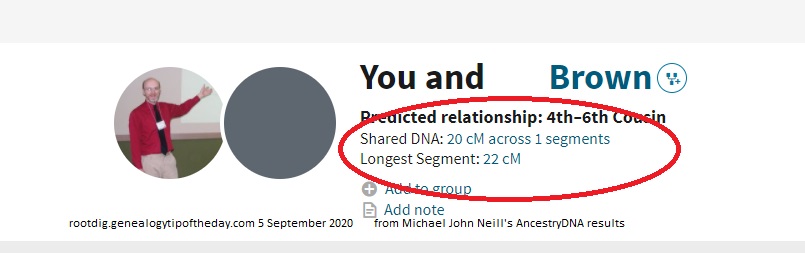
At first it appears confusing. One of my AncestryDNA matches shows us as sharing 20 cM of DNA and yet the longest segment is 22 cM. It’s not a typographical error and the AncestryDNA website is not messed up. It is based on Ancestry’s procedure for handling what are perceived to be bits of shared DNA that are entirely too far back to be practically identifiable to an ancestor. Remember that AncestryDNA is an autosomal test and a shared connection can be anywhere in your tree, not just in the direct paternal or maternal line. That’s one thing that makes working with your AncestryDNA matches challenging.
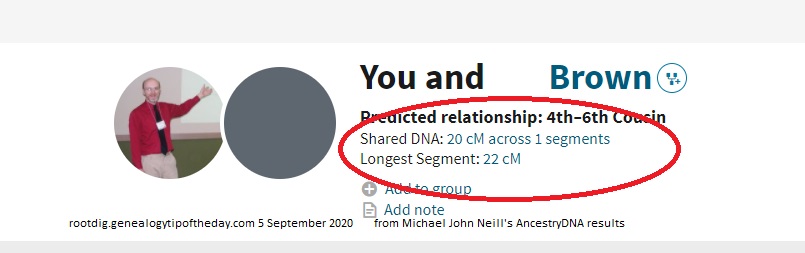
My Brown match and I share 20 cM of DNA across 1 segment and yet the longest segment is 22 cM.
We’re simplifying the AncestryDNA match procedure here a bit for purposes of understanding (read the AncestryDNA white paper for more details). The match process first looks at the shared DNA that the Brown match and I have. In this case that is a segment 22 cM long.
Then the algorithm looks at a much larger body of DNA submissions and notices that a significant number of them have a shared segment of DNA–not just the Brown match and I. That number is large enough that it is believed that that segment must come from much more distant ancestor–one too distant to be determined with any extant records and one that could simply be the result of our families living the same area well before records were kept. That very distant ancestor would be virtually impossible to determine specifically given the generational distance and lack of records. And so that shared segment of DNA–that Brown and I share with so many others that’s likely the result of living in the same area for a long time–is removed from our match since it didn’t come from the common ancestor Brown and I share, but probably from a much more distant one shared by numerous other people. In my case that “distantly shared” DNA was a segment 2 cM in size. That size (of the really distant amount of shared DNA identified as such by Ancestry’s DNA algorithm) can vary. It is not always 2 cM.
Those of us with individuals who lived in one small area for generations before records were even kept are even more likely have these snippets of shared DNA. So if your AncestryDNA match has a longest segment of shared DNA that is larger than your total amount of shared DNA that is the reason. The Timber algorithm has determined that part of what you share is attributable to an unidentifiable distant ancestor.


No responses yet