Downloading images from websites for personal research use is always advised. Then the researcher has the images even if they no longer can access them online for one reason or another.
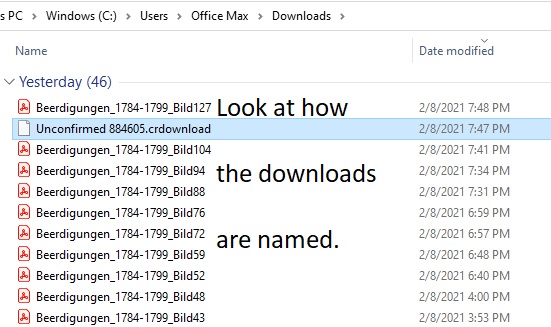
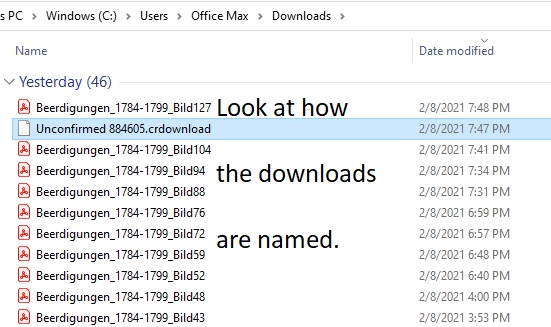
While I should rename files as I download them, I will admit that I do not always do this and often wait until later. I do try and take advantage of the way in which the images are automatically named by the site when they are downloaded. For this reason, before I download too many images from a site, I look in my downloads folder to see how they are named.
This is done to see if there is some way I can use that automatic naming system to my advantage.
I was using Archion.de to view church records for Bad Salzungen, Germany, for members of several families. I was downloading any record that contained one of two names of interest for more detailed review later. I noticed that the file name included the “title” of the record as given in Archion’s system along with the image number. The image number was on my screen as I was viewing it. Instead of renaming the file right after I downloaded the image, I made notes as I was viewing the images and downloading them. There was one note for each image, which included at least the following:
- image number,
- name of interest on the record,
- year of the entries on the page if not obvious,
- anything else of interest.
At the very top of my note, I wrote the name of the website, the date, and other identifying information–including what names I was looking for when I viewed the records.
Between the image name for each individual download and my notes, I need enough information so that I know what I am looking at later; I know why I copied that particular page; and I can create a complete citation. Church records such as these are notorious for not always having page numbers, not including the year of the event on each page, not indicating what type of record is on each page, etc. This is why capturing all that information is crucial–because the creator of the record did not think it was necessary to repeat all that on each entry.
Missing out on clues is what happens when we pull only one entry or one page from a set of records.
I preferred to take the notes by hand on a sheet of paper while viewing and downloading the images, but electronic notes could be taken as well. When I was done viewing one set of images, I moved all the downloaded images to a new folder whose title was the name of the record set (Bad Salzungen–Church Burials–1784-1799) I then took a picture of my notes and put that image in the same folder along with the images.
The key is to track all the information later needed to understand and cite the record. I also find it helpful if the “save record” process is one that does not interrupt the research process. For me, I am more efficient when viewing records that are difficult to read, if I can concentrate on looking through those records and easily save each one as I find them.
Your process may vary. But it is key to capture identifying information about where you got the image, what type of record it is from, and why you copied it–as you copy/save/download the file. Find a way that gets that information and fits well with how you work.
But do not just take download after download and give no thought to how those images are named or organized. That is just asking for additional confusion.


2 Responses
For me, my mother’s reminder, “There’s no time like the present,” has to be the floor of my image-saving practices. I try to respect it even when I’m up against a time-limit like closing time at a library/archive/court house or a free-this-weekend-only situation. I’ve set my browser preferences to always prompt for a folder and filename, so that while I’m already thinking about what’s in that file, I put it somewhere meaningful and give it a decent name (like a person’s name and a year), rather than putting it into the black hole that I call my Downloads folder.
In the case you describe, if I’m short on time, “somewhere meaningful” might be a folder called Intake_Archion_Bad_Salzungen, so I’ll know where the images came from until I can write the citation for them and put them into the folder where they belong for the long run. So far, the browsers I’ve used will default to that folder after I’ve saved into it the first time, so it’s just as quick as defaulting to Downloads. Archion’s own file names look more meaningful than most, so I might not change them immediately, but file names from many sites are gibberish, and I change them to contain items like the ones you wrote on paper.
When I find myself wanting to save images too quickly to do that much, I think it’s a sign that I’m getting too tired to do research. Time to take a break.
No time like the present is exactly correct and time spent at the time is less than the amount of time that will be spent trying to figure things out later.
I love Archion’s file names as they are relatively meaningful. Many others are, just like you say, just about meaningless in terms of being useful later.