Do you know how inheritance “per stirpes” works? Pretend that my second great-grandfather Habben died yesterday […]

From my Genealogy Tip of the Day page on Facebook: I was reminded of this recipe […]
The full-text search at FamilySearch is allowing many of us to make discoveries in local records […]

This is copied and pasted from a personal Facebook status update I wrote today (and unedited). […]

My citation’s not perfect, but that’s not the purpose of this post. The 1856 deed for […]
Wanted to find the death records for a set of relatives last night. Their last child […]
I’ve been using Archion.de to access Evangelical church records in Thuringia, Germany, for the ancestors of […]
We’ve got a few specials running today: Get More Genealogy Tip of the Day today from us directly […]

From a while back: Orville Merton Kile said in 1958 what many genealogists would love to […]
Since restarting Casefile Clues, I’ve been reminded of the importance of writing in genealogy. Even if […]
A great way to build your research skills is to research other families besides your own. […]
For several years, quite a few years ago, I wrote a how-to newsletter, Casefile Clues. It contained […]

At long last, More Genealogy Tip of the Day, packed with genealogy tips and ideas from […]
We’ve released the recording and handout for my new presentation on the full-text searching of local […]
My mother has approximately 12 years of daily calendar entries in various day planners and other […]
On 12 March, we’ll have a webinar on the new full-text search currently being tested at […]
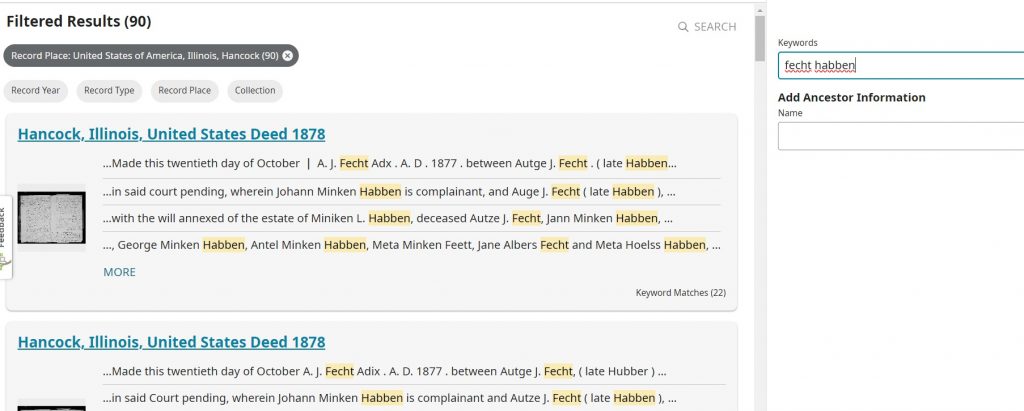
Genealogists who follow the Genealogy Proof Standard are told to conduct a reasonably exhaustive search. How […]

FamilySearch recently announced the full-text search of various local records–particularly probate court and land records at […]

Note: The 4th edition of Evidence Explained has just been released by Genealogical Publishing Company. We’ll […]
I posted this to one of my Facebook pages and decided it said what I wanted […]
If you encourage a family member to take a genealogy DNA test, do you warn them […]
There’s a meme that floats around that purports to show your grandparents waiting to see “Star […]

Apparently Conrad Haase had an “original Paper” copy of his naturalization in his hands when he […]
The recording is now available for my citation webinar–download is immediate. More details are on our announcement […]
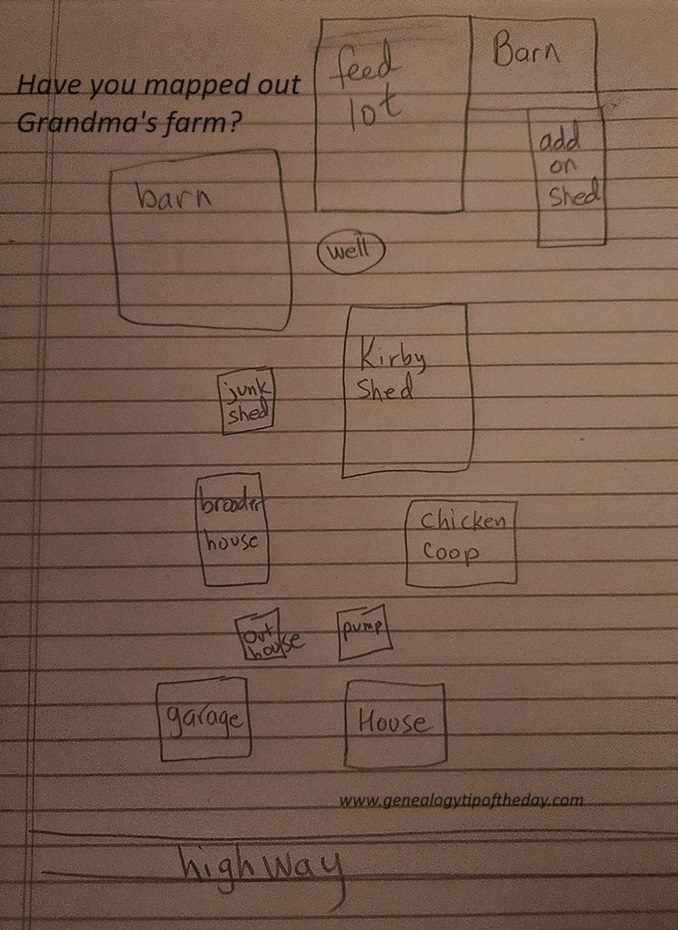
“Made Your Own Map?” appeared recently as a tip of Genealogy Tip of the Day with […]

There’s a practical limit to how far into the network of the non-biologically connected people to […]

Recent Comments