I realize computer programming is often about details and managing exceptions.
I realize that there are reasons comouter programs have default settings. Those settings usually come from initial assumptions about the data being analyzed. Sometimes it is dificult to program around every exception and every nuance in a potential dataset. Default swttings give software a starting point. Apparently Ancestry.com’s default setting is that all people are alive.
Rather ironic for a website devoted to finding dead people.
I decided to experiment with the Ancestry.com app on my phone and the screen display for Sarah Gibson indicated that she was living. This Sarah Gibson is my fourth great grandmother. I realize that currently the file I have contains no dates of vital events for her.
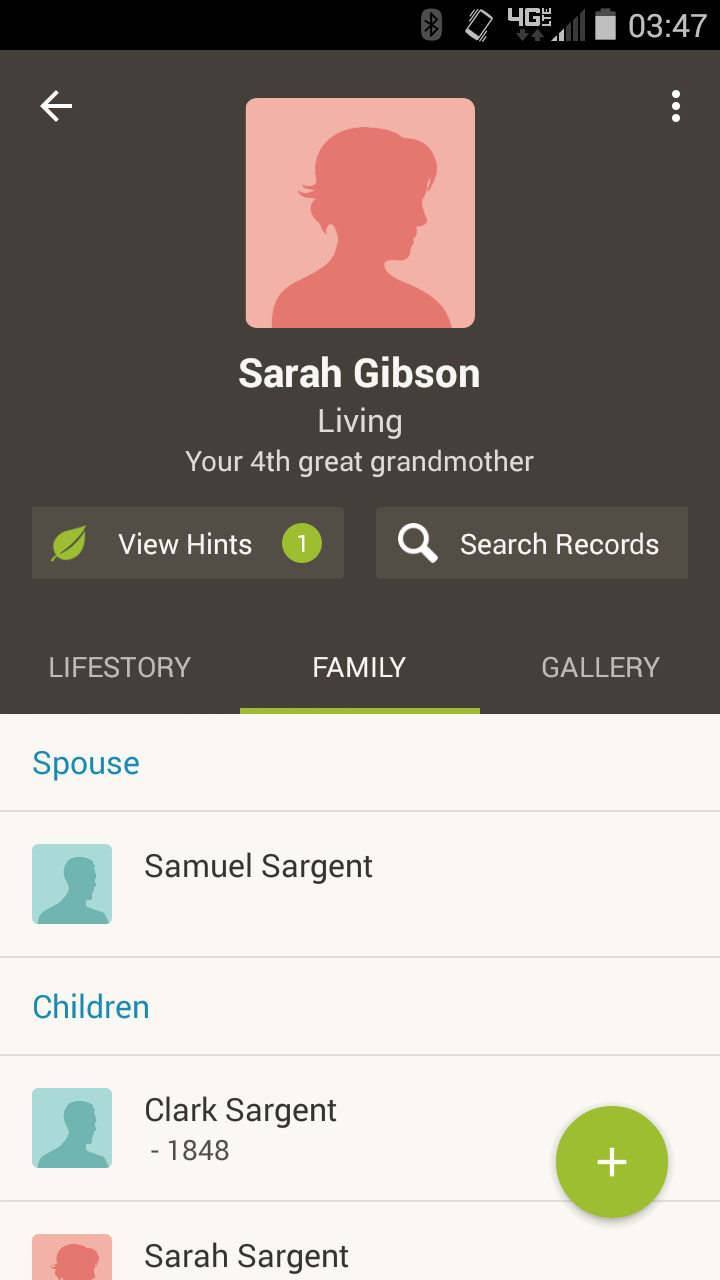
But my Ancestry.com database knows that Sarah Gibson is my fourth great grandmother (it is displayed on the screen after all) and it knows that that I have a death year of 1848 for her son. This database of mine also contains my own date of birth.
But this post isn’t about me.
It’s about Ancestry.com’s default value for Sarah’s “alive or dead” status showing as living.
I know that I have no dates of vital events for her in my file and that everyone is apparently assumed to be alive unless they are shown to be dead. But shouldn’t there be some point where that default value for living changes? Maybe that point could be when the tree displays the fourth great grandmother for someone born in 1968 (which would be me)? Maybe that point could be when the person being displayed has a child who died in 1848? I don’t know, but it should be somewhere.
Ancestry.com touts sophisticated matching algorithms for DNA results. You would think they could figure out that my fourth great grandmother is likely dead and not likely living. That seems a much easier probability to calculate.


4 Responses
I thought Ancestry assumes a person is dead after 100 years. Although my uncle lived to 101!
I have found living people that have information showing up when they should be private, as they are still living. I have also seen people from 1800-1900 listed as living. One of the problems may be how the person adding the information, missed the check for alive or deceased when adding their information. It may not all be Ancestry Fault, but lets remember humans write the coding and they make mistakes, and the people who add the information also make mistakes. If possible we can try to get it corrected, and sometimes we can and sometimes we can’t.
Thank you for your continued hints.
I too, have checked to see why their are no hints on ancestry for a person I thought should have them and found a person living 200 years ago and his name was not Methuselah. But I think the default is living and unless you put in the death date or check mark the dead square then everyone is “living.” Sometimes to find children’s names or other data for living relatives, I check the dead square,and then wait a short while, so the hints will come up and then mark them as living again before leaving ancestry. the green leaves will come up. This works great, and I have obtained lots of info. such as names, marriages, military records, and censuses.
Not to worry, I did a GEDCOM File when Family Tree Maker was Dropped,and most of my Ancestry Tree (for whatever-unknown reasons) was totally messed up, before this I only noticed one mistake on my tree that was a major problem, that was noticing I had Passed away myself!