
It’s really not all that unique of a document. It’s simply a mortgage for $2500 signed […]

I’ve been writing about tombstone pictures on Genealogy Tip of the Day. As time has gone […]
I’ll be giving a webinar on genealogy citation on 28 January–attend live or pre-order a recorded […]
I have my Mother’s original “baby book” from her birth in 1942. The handwriting certainly appears […]
My genealogy motivation: to preserve and share the family history items I have been fortunate enough […]

I posted this picture to Genealogy Tip of the Day as a reminder to look at […]

Ancestry.com refers to Anna Fecht as the step-daughter of my second great-grandaunt. That seems slightly incorrect […]
I’m not retiring from genealogy. But do you track when your ancestor retired from their regular […]
(this appeared in the Ancestry Daily News in 2000 and I thought it worth repeating for those who […]
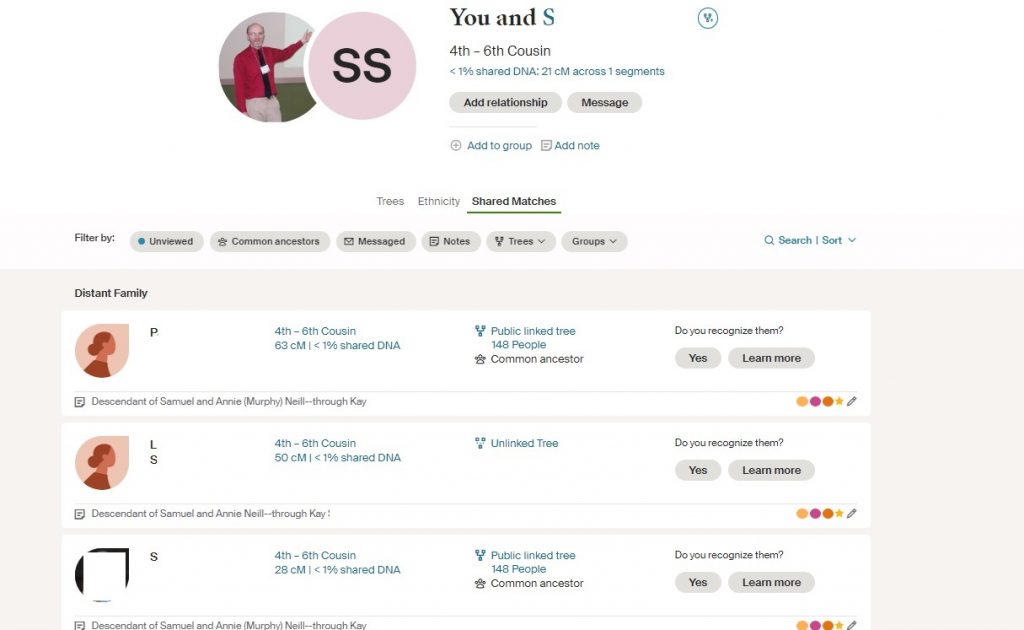
I’m always tentatively excited when I get a new match that appears to fit into my […]
A “reasonably exhaustive search” in the genealogical lexicon means, generally, to look at everything that could […]
In performing a manual search of naturalization records for Hancock County, Illinois, I discovered a large […]
The Library of Virginia Chancery Court records website has added images of court records for Orange […]
We’ve set the dates for our annual trip to the Family History Library in Salt Lake […]
We’ve brought back my trip to the Allen County Public Library in Ft. Wayne, Indiana. There […]

Join me on 10 March to learn more about your US farming ancestors or see our […]
The schedule for the Southern California Genealogical Society’s annual Genealogy Jamboree has gone live and registrations […]
I recently rediscovered a letter my grandmother’s niece wrote to her in 1938. A little Google […]
This was a little thought exercise I undertook partially for my own entertainment and partially to […]

It was December of 1799 and the family of Isaac Rucker, Senr., of Amherst County, Virginia, […]
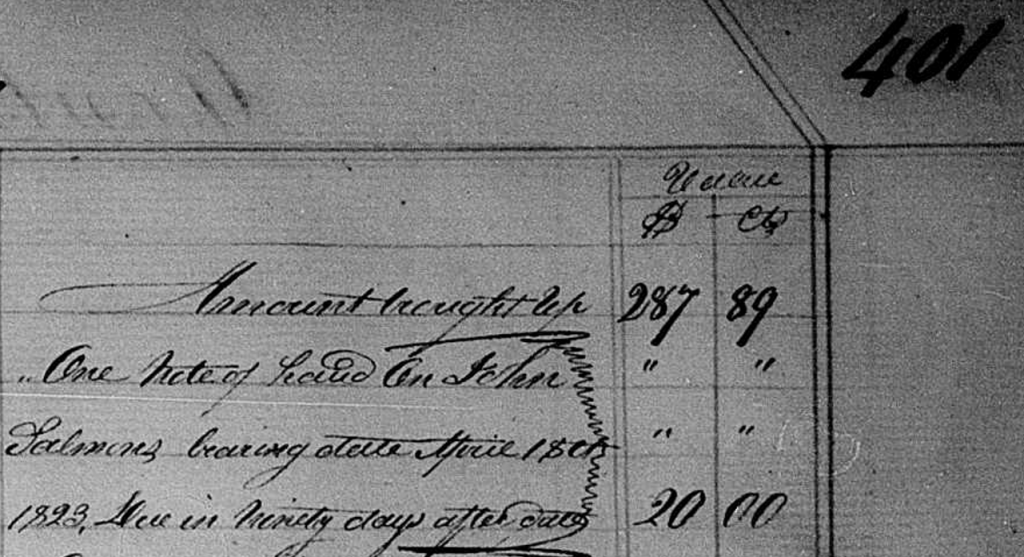
We aren’t always able to get time frames when people die in locations and time periods […]
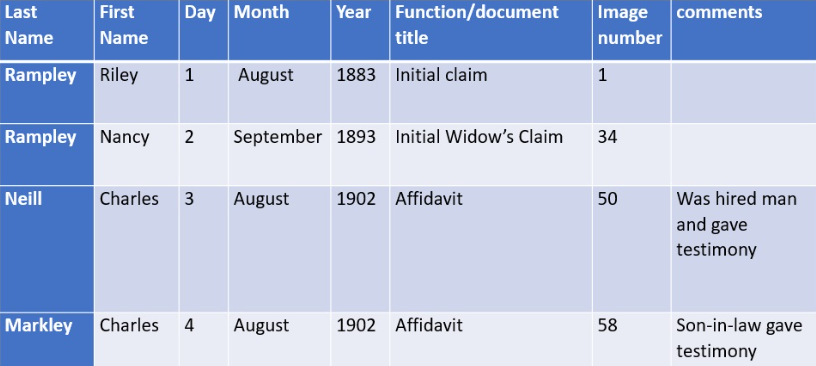
My “Charts, Organizational Approaches, and Color” webinar was held yesterday and was a hit with our […]

I have at least four copies of this photograph of my Ufkes great-grandparents taken around the […]
We are offering this new session on on 12 February 2022. Learn more on our announcement […]
Genealogy Tip of the Day Book

Recent Comments